building a code execution service
September 2022
premise
Recently in our project, AssignExpert, we set out to build a tool that can help educational institutions evaluate programming assignments. This meant that students could submit their programs and we would run them on our servers to grade them. We internally like to call this tool a "HackerRank, but for programming assignments".
Making this happen required a key ingredient: the ability to execute code.
To start with, this looks like forking a process that would compile and run the code. Our servers just need to have the compiler and/or the runtime environment for the code's programming language. It looks trivial, except it isn't.
issues
The code that comes in from random sources could be malicious.
What if the program tries to steal information from our files and uses our network to send them to some other server?
What if the program tries to consume all the available memory?
In an unprotected form, the program could do anything. What is needed is a way to control what a process can see and what resources a process can use. This act of shielding your system from potentially malicious code is called sandboxing.
sandboxing
A whole lot of research work has gone into implementing sandboxing. All of the tools rely on the following fundamental features of the Linux kernel.
namespaces - namespaces give your process a different view of system resources. For instance, I can give a process an independent set of process IDs from other namespaces. It means two processes, within their respective namespaces can happen to fork new processes with the same process IDs and be unaware of each other. This is one kind of a namespace. As of Linux kernel 5.6, there are 8 such kinds of namespaces. And a process can have multiple namespaces, allocated to it using flags while creating the process.
cgroups - cgroups help you in limiting resource usage for your processes. The resource could be CPU, memory, network, disk, etc.
seccomp - seccomp lets you decide what system calls your process can make.
Following is a small list of tools that are built on top of the above features of the kernel.
firejail - firejail is a lightweight sandboxing program written in C. It allows a process and all its descendants to have their own private view of the globally shared kernel resources, such as the network stack, process table, mount table.
nsjail - NsJail is a process isolation tool for Linux. It utilizes the Linux namespace subsystem, resource limits, and the seccomp-bpf syscall filters of the Linux kernel.
sandboxify - This is a tool built by CloudFlare which lets you do system call filtering via seccomp rules.
docker - All right, calm down, keyboard warrior. I know Docker isn't explicitly built for sandboxing. But it uses the aforementioned features of the linux kernel in order to achieve containerization. And it happens to have great community support as well. So I spent some time looking into the possibility of using docker as my tool to do sandboxing. And it turned out, it is possible to do so! You can create docker images compatible with each programming language you want to support. Every time you want to run some code, you create a container, run your code inside the container, extract the outputs, and destroy the container.
Below is therefore a comparison I did before finally locking down on docker as my tool.

using docker
- Firstly, we need to create a few docker images. These docker images would contain the compiler and/or the runtime environment for a given programming language. Below is one such docker image setup for running some C code.
FROM alpine:latest <br>
ENV TIME_LIMIT 0 <br>
ENV TC_COUNT 0 <br>
RUN apk add build-base <br>
COPY c.sh . <br>
RUN ["mkdir", "ae"] <br>
RUN ["chmod", "+x", "c.sh"] <br>
CMD ["/bin/sh", "-c", "./c.sh ${TC_COUNT} ${TIME_LIMIT}"] <br>
When the container is created, it will run the c.sh script which looks like this:
#!/bin/sh <br>
gcc /ae/submission.c -o /ae/submission 2> /ae/compile.txt; <br>
i=1 <br>
while [ "$i" -le "$1" ] <br>
do <br>
timeout $2 /usr/bin/time -f '%M-%e' -o /ae/stats$i.txt /ae/submission < /ae/input$i.txt > /ae/ <br>submission$i.txt 2> /ae/runtime$i.txt;<br>
echo $? > /ae/timeout$i.txt; <br>
i=$(( i + 1 )) <br>
done <br>
We need to set up Dockerfiles and shell scripts for all our programming languages. You can find all of them over here.
Next, we create a new directory with a unique name. This directory will be mounted to our docker container and will be used for dumping all the outputs from the program.
Next, we create and run our container. We end up with a bunch of text files giving us various metrics and info about the program (compile error, stdout, stderr, time taken, memory taken).
Next, We process these text files and compute our result. We display our results.
Finally, we destroy the container and the directory we created.
jobs
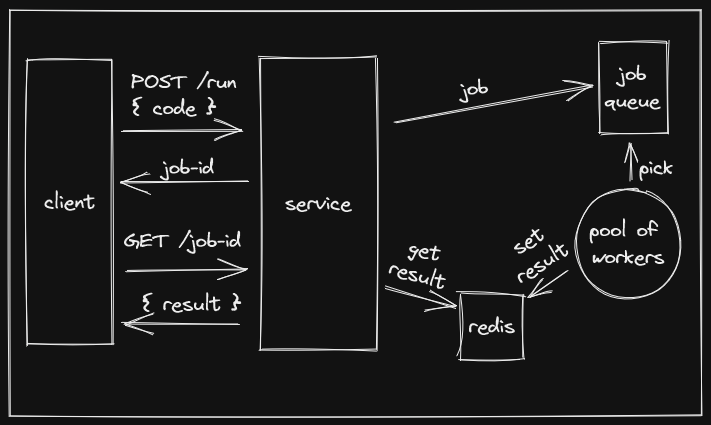
Okay, now we know that we need to spin up a docker container every time we want to run some code. This task usually takes more than a few milliseconds. And our goal is to expose this functionality through some HTTP endpoint. Latency can become a bottleneck if not managed correctly. We would want an immediate answer as soon as we make a submission. It would help us to put these tasks in a job queue and give the client a unique job-id which can be used to query the status of the job. This is precisely what I ended up doing. I used bullmq to enable this. The job-id is a uuid generated just before the job goes into the queue. A benefit here is that this job-id can also be used for having a unique directory name that is mounted to the container. bullmq uses Redis as its storage layer. So the flow now looks like this:
- Client sends some code.
- We create a unique
job-idand return it to the client immediately. - We use this
job-idand put the client's code in the job queue. - Some worker picks the code up from the queue.
- The code gets processed via docker, as described above.
- We store the processed result in Redis. (
set job-id result) - Meanwhile, client keeps polling the server using the
job-id, for which we do aget job-idon our Redis instance. Server returns the result if it is available.
Below is a high-level architecture diagram representing the complete flow.
outcome
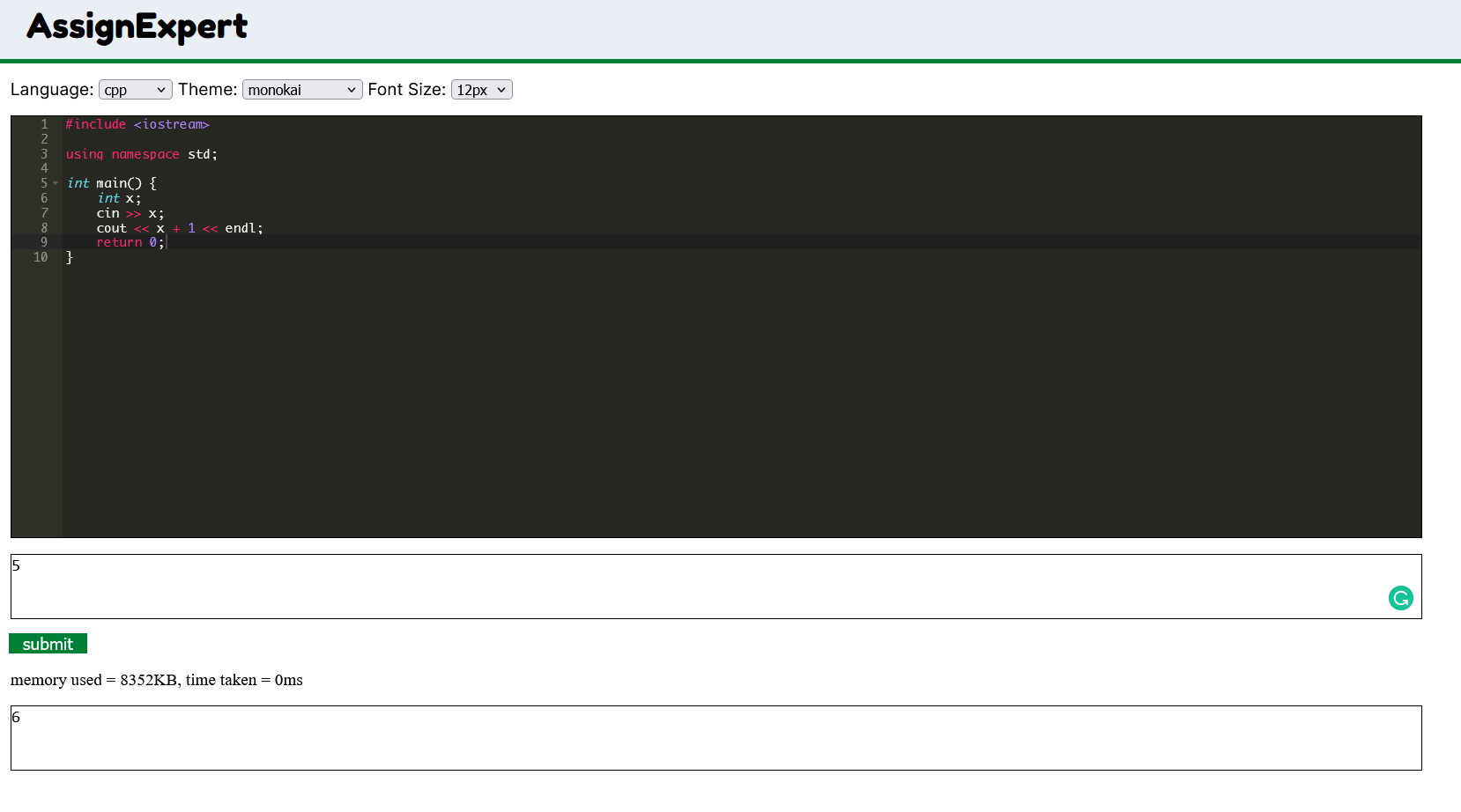
Putting all the pieces together and giving them a minimal UI, here is what I came up with!
conclusion
It was fun building this service. When you see something you have been working on for some time, come alive, it is a great feeling. But the biggest takeaway for me is my newfound interest in the inner workings of containerization. This is an exciting space to dig into. And I hope build more things around this. Happy programming :)
Vivek
<- back to home